[1/4] PostgreSQL : Fondamentaux et mécanismes internes
![[1/4] PostgreSQL : Fondamentaux et mécanismes internes](https://storage.ghost.io/c/57/f5/57f50b2f-668c-4e9e-96c0-ad9c84c7c513/content/images/size/w1200/2025/11/1_VFsfbE4qWtLO80dPujkACQ.webp)
Par Nicolas Favier !
À propos
Bien souvent, la compréhension de l’usage des bases de données se résume à : comment stocker mes tables et exécuter quelques requêtes.
Mais dès que les performances entrent en jeu, et c’est souvent le cas, on peut vite se sentir perdu : soit par manque de compréhension, soit par manque d’outils, soit tout simplement par manque d’expérience.
Je me lance dans l’écriture d’une série de 4 d’articles pour vous donner tous les tips et explications que j’ai accumulés sur mes années de devs pour mieux comprendre Postgres.
J’ai fait de mon mieux pour structurer et créer un fil conducteur, mais sentez-vous libre de lire les parties dans l’ordre qui vous convient.
1. Base de données relationnelles
Dans cet article, nous allons parler de bases de données relationnelles, et plus particulièrement de PostgreSQL, qui est un Système de Gestion de Bases de Données Relationnelles (SGBDR).
Cela signifie qu’il appartient à la famille des moteurs de bases de données qui reposent sur la théorie mathématique de l’algèbre relationnelle.
PostgreSQL permet l’accès et la manipulation des données contenues dans des relations (ou tables) en utilisant le langage SQL, qui définit des opérateurs relationnels (SELECT, WHERE, FROM, etc.) ainsi que des opérateurs non relationnels, comme : ORDER BY / GROUP BY / DISTINCT / HAVING et les sous-requêtes.
PostgreSQL respecte les principes ACID, essentiels pour garantir la fiabilité des transactions :
- Atomicité : Les opérations sont regroupées en transactions, qui s’exécutent totalement ou pas du tout.
- Cohérence : Le système garantit l’intégrité des données via des contraintes : UNIQUE, NOT NULL, CHECK, etc.
- Isolation : Chaque transaction s’exécute comme si elle était seule, grâce au MVCC (Multi-Version Concurrency Control) que nous détaillerons plus loin.
- Durabilité : Les données sont garanties comme persistantes grâce à la journalisation (WAL) et à la double écriture, qui méritent, elles aussi, un paragraphe dédié.
Pourquoi se focaliser sur Postgres ?
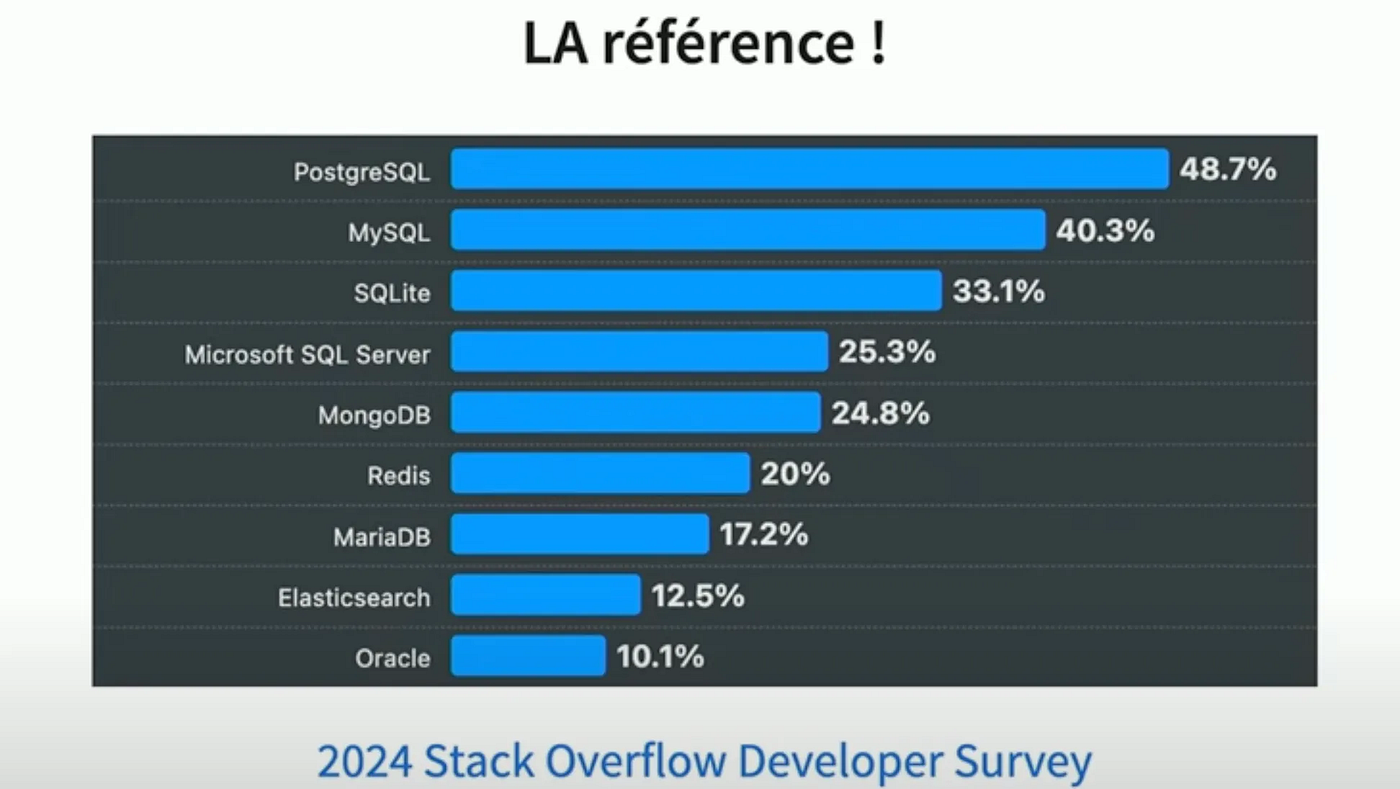
Depuis plus de 20 ans, il est porté par une communauté internationale, décentralisée et très dynamique. Chaque année, une nouvelle version majeure est publiée avec de nouvelles fonctionnalités, ce qui en fait le SGBD le plus innovant du secteur.
2. MVCC
Dans les systèmes de gestion de bases de données comme PostgreSQL, chaque ligne d’une table n’est pas directement modifiée ou supprimée. Regardons un peu plus en détail comment Postgres gère les changements en base. C’est grâce au MVCC (Multi-Version Concurrency Control), chaque opération (INSERT, UPDATE, DELETE) génère une nouvelle version de ligne. Une table peut donc stocker plusieurs versions d’une même ligne.
Chaque version contient deux informations clés :
- xmin : identifiant de la transaction qui a créé cette version.
- xmax : identifiant de la transaction qui a invalidé cette version (par un UPDATE ou un DELETE).
Une mise à jour (UPDATE) ne modifie pas la ligne existante, elle :
- Crée une nouvelle ligne (nouvelle version) avec un xmin plus récent.
- Invalide l’ancienne version en y ajoutant un xmax correspondant.
Exemple :
INSERT(TX = 100)
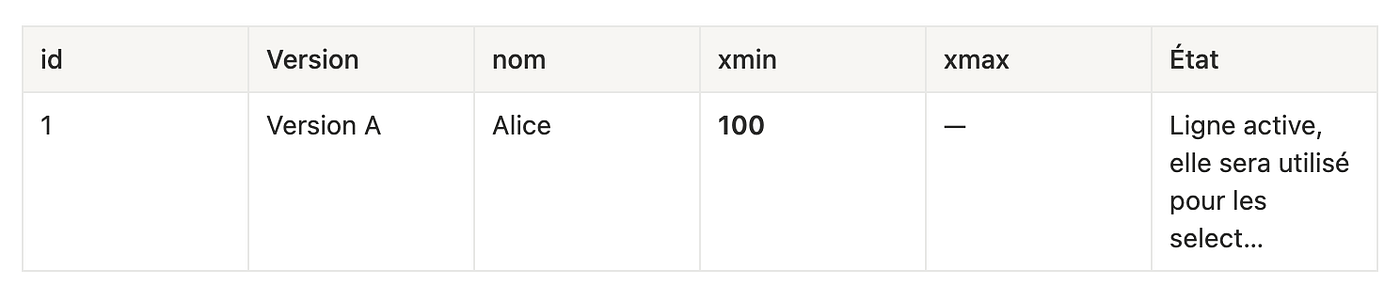
Une seule version : ligne logique id = 1, créée par la transaction 100.
UPDATE nom = 'Alicia'(TX = 101)
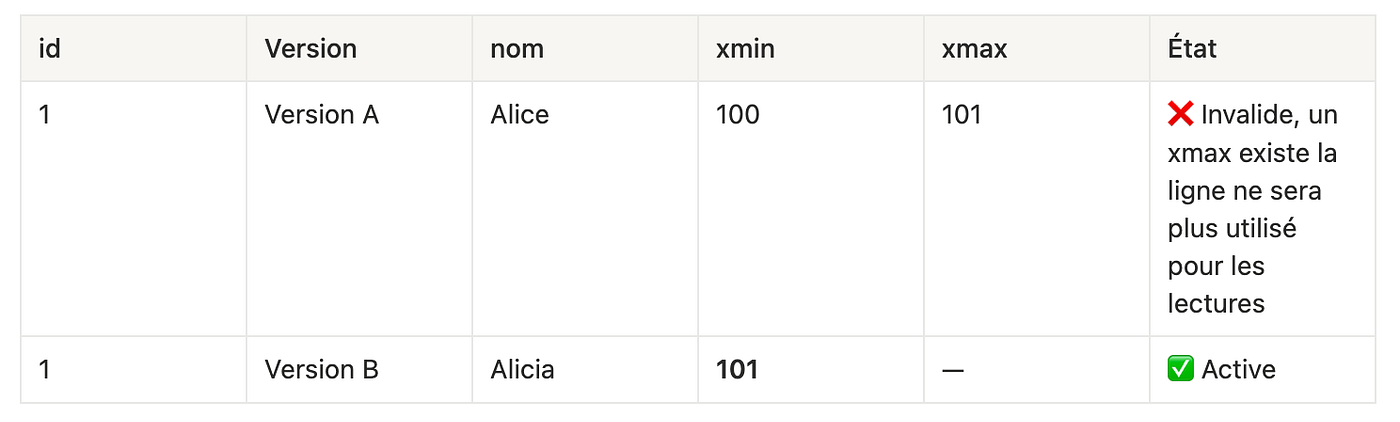
L’UPDATE a créée une nouvelle version (B), l’ancienne (A) est invalidée.
DELETE(TX = 102)

La ligne est supprimée → dernière version reçoit xmax = 102.
Ce sytème permet à une transaction de ne regarder que les changements effectif avant son executions, cela permet l’isolation de nos transaction.
3. Le vacuum
Toutes ses lignes invalidées, appelées dead-row, vont ralentir les requêtes, car le moteur doit filtrer les anciennes versions. On appel Bloat le ratio entre le nombre de ces lignes mortes et le nombre de lignes totales.
Il faut donc les nettoyer, et ca tombe bien c’est le rôle du Vacuum.
Le process autovacuum permet de lancer automatiquement ce Vacuum selon certains seuils :
- Nombre de lignes mortes.
- La proportion de lignes mortes par rapport à la taille totale de la table. (souvent autour de 20% de bloat)
Une ancienne version de ligne ne sera recyclée qu’à la condition que toutes les transactions en cours n’aient plus besoin d’accéder à cette vieille version.
L’avantage de ce sytème est qu’il ne nécessite pas de poser de verrou lourd et n’entraîne donc pas le blocage des sessions concurrentes.
Il faut tout de même noter que le VACUUM “normal” ne libère pas l’espace disque au niveau système : Il nettoie logiquement les lignes mortes, marque l’espace occupé par ces lignes comme réutilisable. Mais l’espace n’est pas rendu au système de fichiers.
Pour aller plus loin et nettoyer physiquement ces lignes, on peut lancer un VACCUM FULL qui va :
- Copier la table dans un nouveau fichier.
- Éliminer complètement les lignes mortes.
- Réduire la taille physique du fichier sur disque.
- Réorganiser les lignes de façon compacte.
- (Cette opération n’est pas lancée automatiquement)
⚠️ Cette opération verrouille la table en mode exclusif donc il ne pourra pas y avoir de lecture ou d’écriture pendant l’opération. Pour plus de tranquilité préférez le faire tourner la nuit ou en cas de gros problèmes.
Lors de ce VACUUM FULL il faut tout réécrire sur le disque, les temps sont donc dictés par la vitesse d’écriture de vos disques, pour vous donner un ordre de grandeur une centaine de giga prendrais entre 15 et 30 minutes. Il ne faut pas négliger ces temps dans vos opérations de maintenance. Si dans votre usecase la table est très grande et que VACUUM FULL serait trop coûteux en downtime vous pouvez utiliser pg_repack. C’est une extension postgres qui va créer une nouvelle version de la table en arrière-plan, copier les données en excluant les lignes mortes et construit les structures de façon compacte. Ensuite, il bascule la nouvelle version de manière atomique, ce qui minimise le temps de verrouillage.
Attention, cette manipulation vient aussi avec son cout, elle prend beaucoup plus de place sur votre disque.
Maintenant que nous comprenons mieux les systèmes sous-jacents, creusons un des problèmes de performance récurent que l’on retrouve dans nos applications :
Prenons le cas d’un UPDATE de toute une table avec beaucoup de données. Cet update va entraîner la duplication de toutes les lignes affectées. L’espace occupé sur le disque de cette table va doubler, en attente du processus autovacuum (qui devrait se déclencher juste après).
Tant que ce processus ne passe pas, on va avoir une dégradation des performances, car les scans séquentiels ou les index vont passer sur des données mortes.
Par ailleurs, la mise à jour d’une ligne, va créer une nouvelle version de cette ligne, ce qui force le sytème à mettre à jour les index : la dernière version de l’enregistrement a changé d’emplacement physique.
Notre système est donc surchargé et plus lent, dans la plupart des cas les impacts sont minimes, car les updates n’affectent pas l’intégralité de la table. Mais les impacts sont souvent ressentis lors de scripts de migration par exemple.
Que faire ?
- Préférer CREATE TABLE AS SELECT + DROP + RENAME si possible
- Segmenter le script en plusieurs petits, entrecoupé de Vacuum, comme ça les lignes seront réutilisées, et nettoyées au fur et à mesure
Subtilité : PostgreSQL possède une optimisation interne appelée HOT updates (Heap-Only Tuples). Elle permet d’éviter la création de versions multiples des lignes et donc de réduire le besoin de VACUUM. Mais cela ne marche que dans certains cas (exemple si un index est impacté, il ne sera pas utilisé).
Donc toujours garder comme bonne pratique de vérifier l’exécution de gros update ou de script sur une volumétrie comparable à la production, pour devancer les problèmes de lenteur ou les besoins de vaccum.
4. Les Locks
Creusons un peu plus le fonctionement du MVCC.
4.1 Utilité des locks
Imaginez que l’on ait une table comptes avec le solde des utilisateurs :

Supposons deux transactions simultanées :
- T1 : Alice veut retirer 30€ de son compte (UPDATE comptes SET solde = solde — 30 WHERE id = 1).
- T2 : Alice veut consulter son solde (SELECT solde FROM comptes WHERE id = 1).
Sans MVCC et sans locks :
- T2 pourrait lire le solde en cours de modification par T1, et obtenir un résultat incohérent (par exemple 70€ alors que la transaction T1 n’est pas encore terminée).
- Si une autre transaction tente de faire un retrait simultanément, il y aurait risque de double dépense ou d’écrasement des données.
Avec MVCC et les row-level locks :
- T2 lit un instantané cohérent du compte avant la modification de T1, donc il voit toujours 100€ tant que T1 n’est pas terminé.
- T1 verrouille la ligne pendant son UPDATE, empêchant une autre transaction d’écrire sur la même ligne jusqu’au COMMIT.
Ce système garantit que les lectures ne bloquent pas les autres lectures, mais les écritures concurrentes sont coordonnées pour maintenir l’intégrité des données.
Grâce au MVCC, la plupart des lectures (SELECT) ne nécessitent pas de verrou lourd. Chaque transaction voit un instantané cohérent de la base, ce qui permet à plusieurs transactions de lire les mêmes données en même temps sans se bloquer.
4.2 Row-level locks
Lorsqu’une transaction effectue un UPDATE ou un DELETE :
- PostgreSQL verrouille uniquement la ligne ciblée.
- Ce verrou empêche d’autres transactions de modifier la même ligne jusqu’à la fin de la transaction.
- L’ancienne version de la ligne reste visible pour les transactions qui en ont encore besoin selon leur instantané.
Exemple :
- T1 fait UPDATE sur la ligne 1 → crée version B et verrouille la ligne.
- T2 fait SELECT → voit la version A si elle a commencé avant T1, aucune attente.
- T3 tente UPDATE → doit attendre que T1 se termine.
4.3 Table-level locks
Certaines opérations nécessitent un verrou plus large :
- VACUUM → pas de verrou lourd.
- VACUUM FULL → verrouillage exclusif, aucune lecture ni écriture possible.
- ALTER TABLE ou CREATE INDEX CONCURRENTLY → peuvent prendre des locks, certains étant concurrents pour minimiser l’impact.
4.4 Fonctionnement interne
Les row-level locks ne sont pas dans les lignes, mais dans une lock table en mémoire. Chaque lock est identifié par :
- L’OID de la table,
- L’identifiant de la ligne (ctid),
- L’ID de la transaction.
Les Row-level locks sont libérés à la fin de la transaction (COMMIT ou ROLLBACK) et les Table-level locks peuvent durer toute la commande ou toute la transaction, selon le mode de lock choisi. Si une transaction demande un lock déjà détenu, elle attend le prochain lock en étant placé dans une file d’attente dans la lock table. Et PostgreSQL applique une politique FIFO pour la gestion de ses locks.
Pourquoi ce fonctionement nous interesse ? Par ce que des fois ca ne marche pas comme attendu et on fini avec l’erreur tristement connue deadlock.
4.5 Deadlocks
Les verrous permettent de garantir la cohérence des données, mais ils peuvent parfois se bloquer mutuellement : c’est ce qu’on appelle un deadlock.
Un deadlock survient lorsque deux transactions attendent chacune un verrou détenu par l’autre. Par exemple :
- T1 met à jour la ligne 1 puis veut mettre à jour la ligne 2.
- T2 met à jour la ligne 2 puis veut mettre à jour la ligne 1.
Chaque transaction attend la libération du verrou détenu par l’autre : aucune ne peut avancer, PostgreSQL détecte alors le blocage et interrompt l’une des deux pour débloquer la situation.
Le message typique est :
ERROR: deadlock detected
DETAIL: Process 12345 waits for ShareLock on transaction 67890; blocked by process 54321.
Process 54321 waits for ShareLock on transaction 12345; blocked by process 12345.
HINT: See server log for query details.
CONTEXT: while updating tuple (0,1) in relation "comptes"
Pour diagnostiquer un deadlock ou des verrous bloquants, on peut interroger les vues système suivantes :
SELECT * FROM pg_locks l JOIN pg_stat_activity a ON l.pid = a.pid;
Cela permet d’identifier quelles transactions se bloquent entre elles. La résolution passe souvent par une analyse applicative :
- réduire la taille des transactions,
- accéder aux ressources toujours dans le même ordre,
- découper les transactions longues ou imbriquées inutilement.
Ainsi, une bonne conception côté code reste la clé pour prévenir les deadlocks.
5. Le WAL (Write Ahead Log)
Le WAL est au cœur du système de fiabilité de Postgres. Il s’agit d’une suite de fichiers binaires qui contiennent toutes les modifications effectuées sur la base, enregistrées avant leur application dans les fichiers de données. Ces fichiers permettent la reprise après erreur de postgres mais aussi aux développeurs d’effectuer des backups ou des restaurations.
Lorsqu’une transaction modifie une donnée, Postgres :
- Met à jour la copie en mémoire (dans le shared buffer).
- Écrit immédiatement une entrée dans le WAL (séquentiellement, donc très rapide). Chaque segment contient une séquence d’enregistrements : INSERT, UPDATE, DELETE, création de tables, etc.
- Ne met pas tout de suite à jour le fichier de table sur disque : ce sera fait plus tard, lors d’un checkpoint.
Une transaction est considérée comme validée uniquement lorsque l’entrée correspondante est écrite sur disque dans le WAL.
Ce principe garantit qu’en cas de crash, Postgres peut relire le WAL pour rejouer ou annuler les transactions en cours et cela va nous aider pour construire des systèmes de restaurations !
Il est assez simple d’intéragir avec ces fichier, tous se fait avec postgres. Pour lister les WAL actifs :
ls $PGDATA/pg_wal
Savoir quels WAL sont nécessaires pour restaurer :
SELECT pg_current_wal_lsn();
SELECT * FROM pg_stat_wal;
On peut utiliser ce système pour faire du point-in-time recovery. Cela nous permettra de revenir à n’importe quel état de notre DB. Très utile si vous avez raté un script, eu un incident ou ce genre de panique.
Pour ce faire, il va falloir dans un premier temps activer l’archivage des WAL ( archive_mode = on).
Une fois activé, Postgres copiera au cours de l’eau les WALs dans un dossier/stockage externe. Vous pourrez récupérer lire ou rejouer ces actions depuis ce dossier.
Pour la restauration, cela nécessite quelques steps, mais rien de très compliqué :
- On arrête Postgres.
- On reset la base.
- On copie les WALs jusqu’ à la date de restauration voulue.
- On ajoute un fichier indiquant à Postgres de démarrer en mode recovery.
- Postgres va redémarrer et appliquer les WALs.
Si vous mettez ou avez ce système en place, assurez-vous d’avoir une documentation à jour et de tester (annuellement au moins) la restauration. Le jour où vous devez restaurer votre base, vous aurez bien d’autres problèmes que de prendre le temps de découvrir le process.
Conclusion
Merci de m’avoir suivi jusqu’au bout ! Nous avons déjà tombé un bon morceau, et tu devrais maintenant mieux comprendre les rouages internes de PostgreSQL. Ces mécanismes fondamentaux sont la clé pour maîtriser l’outil, anticiper ses limites et diagnostiquer efficacement les problèmes de performance.
Pour résumer, nous avons vu :
- Le MVCC — PostgreSQL n’a rien de magique : il gère simplement plusieurs versions d’une même ligne grâce aux identifiants
xminetxmax. Ce principe garantit l’isolation des transactions sans blocage excessif. - Le VACUUM — essentiel pour nettoyer les anciennes versions et maintenir de bonnes performances. Attention lors de grosses opérations : un
VACUUM FULLpeut être utile, mais il faut savoir quand et comment l’utiliser. (Nous approfondirons la partie “debug & optimisation” dans les prochains articles.) - Les locks — souvent le symptôme d’une logique applicative trop complexe ou de transactions trop longues. Comprendre leur fonctionnement aide à concevoir un code plus robuste et à éviter les deadlocks.
MVCC, VACUUM et Locks reviennent régulièrement quand on utilise PostgreSQL. Les maîtriser, c’est déjà franchir un grand pas vers une utilisation plus fine et performante de ta base de données.
Dans le prochain chapitre, nous irons plus loin du côté des optimisations, des plans d’exécution et des outils de diagnostic pour décortiquer encore davantage les performances de Postgres.
À très bientôt pour la suite !